





LABJE e ITAINNOVA analizan la argumentación jurídica de la custodia de hijos menores de edad, mediante Big Data
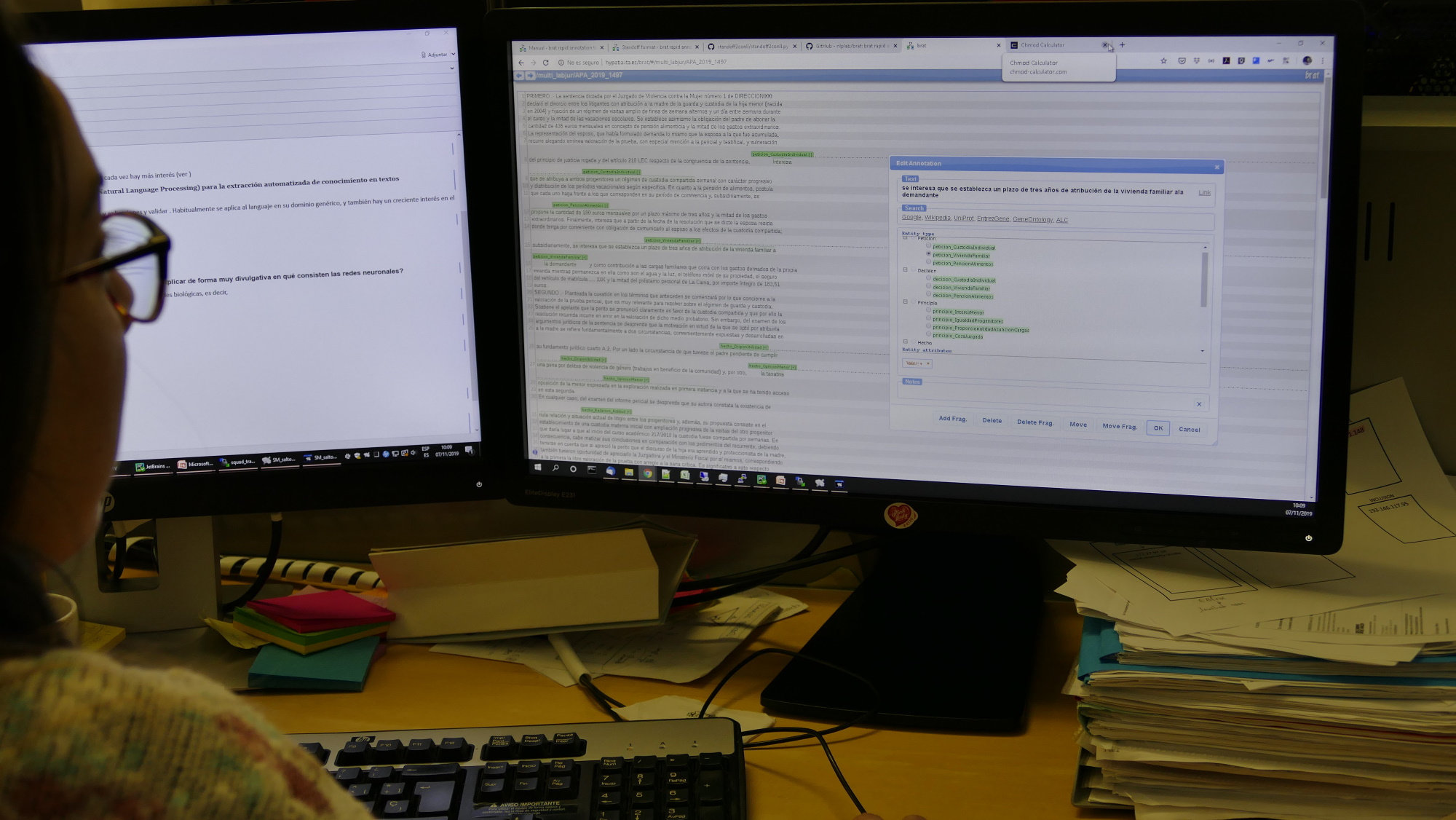
El proyecto se encuadra dentro del estudio de las aplicaciones de la inteligencia artificial en el ámbito jurídico y su objetivo es el desarrollo de una herramienta, basada en redes neuronales, capaz de identificar determinadas entidades en el texto de las resoluciones judiciales. Constituye una experiencia, pionera en nuestro país, de utilización del procesamiento de lenguaje natural (NLP, Natural Language Processing) para la extracción automatizada de conocimiento en textos jurídicos. El ámbito en el que se centra son las sentencias referidas a la custodia (compartida o individual) de los hijos menores de edad.
El Gobierno de Aragón financia el proyecto dentro de la convocatoria de subvenciones para el desarrollo de proyectos de investigación en líneas prioritarias y de carácter multidisciplinar para el periodo 2018-2020. El equipo está coordinado por José Félix Muñoz Soro, investigador ARAID (Agencia Aragonesa para la Investigación y el Desarrollo). Lo forman doce profesores de la Universidad de Zaragoza, en su mayoría pertenecientes al grupo de investigación de referencia Gestión Jurídica de Negocios, Instrumentos y Organizaciones Innovadoras (LegMiBIO), cuyo investigador principal (IP) es Pedro Bueso Guillen; cinco investigadores de ITAINNOVA, pertenecientes al grupo Integración y desarrollo de sistemas de Big Data y eléctricos (IODIDE), cuyo IP es Rafael del Hoyo Alonso; y dos juristas contratadas para el proyecto.

Las tareas preliminares comenzaron en julio de este año. Primero, partiendo de un estudio exploratorio de las resoluciones de la jurisdicción civil en Aragón, se seleccionó el ámbito sobre el que se centra el proyecto. Seguidamente se definieron los tipos de entidades a considerar y luego, para cada uno de ellos, las entidades más relevantes relativas al ámbito del estudio. Finalmente, se elaboró un lenguaje de etiquetado y se asociaron las entidades con sus correspondientes etiquetas. También se desarrolló una metodología para el etiquetado, se llevó a cabo el procedimiento para la incorporación de las dos juristas encargadas del mismo y se puso a punto una herramienta informática específica, basada en Brat.
El conjunto de sentencias etiquetadas servirá de base para los ciclos de entrenamiento/reconocimiento/validación. Si estos tienen éxito, la herramienta ira adquiriendo la capacidad para conocer cuáles han sido las peticiones realizadas por la parte actora en el procedimiento y la decisión del tribunal respecto a las mismas, así como la habilidad de identificar los argumentos utilizados en la justificación de dicha decisión, distinguiendo entre principios jurídicos, justificaciones normativas y justificaciones fácticas.
El proceso de etiquetado de sentencias está en marcha desde hace un mes. Se espera comenzar con la elaboración de modelo a principios de 2020 y seguir refinándolo, mediante sucesivos ciclos de entrenamiento/reconocimiento/validación, hasta el verano del mismo año, fecha en que finaliza el proyecto. Tanto el conjunto de sentencias etiquetadas como el modelo se compartirán, bajo una licencia libre, en GitHub.
El equipo del proyecto es consciente de la gran dificultad que encierra el tratamiento de un lenguaje tan complicado, en la forma y en el fondo, como es el jurídico. Pero se espera obtener al menos una primera aproximación que permita valorar la capacidad del deep learning para llevar a cabo un análisis de las resoluciones judiciales basado en las entidades y conceptos que habitualmente utilizan los juristas. De obtenerse resultados apreciables ello proporcionaría a los investigadores una potente herramienta para avanzar en sus trabajos sobre «minería de argumentos» (argument mining) aplicada a la argumentación jurídica, así como para analizar, tanto desde una perspectiva dogmática como sociológica, las resoluciones judiciales de los tribunales aragoneses y españoles.
ita
OTROS ARTÍCULOS
-

La directora del ITA asiste al Observatorio Aragonés de la Automoción
ITA | Martes, 11 Marzo 2025
-

El ITA colabora en la Semana del Hidrógeno de Aragón
ITA | Lunes, 10 Marzo 2025