





¿Qué es un Data Lake? Definición, creación y ejemplos.
Uno de los desafíos tecnológicos a los que se enfrentan las empresas es el crecimiento de los datos: cada dos años se duplica la cantidad de datos gestionados. Terabytes, petabytes y hexabytes son ya términos de uso común, en todos los sectores, cuando hablamos de capacidad de almacenaje. A este hecho se añaden otros dos, alrededor del 80% de esos datos es información no estructurada (textos, videos, etc.) y, al menos, el 50% de los datos gestionados por la empresa (de su know-how) se almacena y gestiona fuera de sus centros de datos, sin protección y creando brechas de seguridad.
Foto principal:
Proyecto MATUROLIFE. Prototipos de sillón desarrollado en MATUROLIFE y de la visualización de datos incorporados al data lake.
Índice
- Definición de data lake
- Características de un data lake
- Proceso de creación de un data lake
- Ejemplos de data lakes
Definición de Data lake
Un data lake es un conjunto centralizado de repositorios de datos capaz de contener vastas cantidades de datos crudos (sin procesar), tanto estructurados (bases de datos convencionales) como no estructurados, descritos mediante meta datos (que identifican el conjunto de datos al que pertenece cada dato) y que hace disponibles los datos bajo demanda. La capacidad de almacenamiento de un data lake puede escalar de manera masiva (usando plataformas como, entre otros, Hadoop o Apache Spark). Un data lake permite descubrir, analizar y generar informes de los datos que contiene. La consulta y búsqueda de datos se realiza utilizando tecnologías tradicionales de bases de datos (en datos estructurados) o utilizando vías alternativas como indexación (de texto, video, audio) y bases de datos NOSQL. Además, sus datos, se hacen disponibles de manera sencilla para usuarios sin conocimientos técnicos profundos.
Frente a los Datawarehouse y Data Marts tradicionales, un data-lake no describe el formato de los datos (no hay un esquema disponible) hasta que se necesitan. Retrasar la categorización de los datos, desde el punto de su captura hasta su punto de uso, permite realizar operaciones analíticas que transcienden un esquema ya adoptado.
Características de un Data Lake
Las características (deseables) de un Data Lake, que le distinguen de los repositorios tradicionales, son:
- Tener una arquitectura escalable con una habilidad alta de crecer con el volumen de los datos. Esto les permite conservar todos los datos para cuando puedan ser utilizados, añadir nuevas fuentes, etc.
- Poseer herramientas para realizar Gobernanza de los datos: gestión de políticas de retención, disposición, identificación de datos a ser retirados, gestión de leyes y normas de aplicación (acceso a fuentes, RGPD, licencias de uso, licencias de distribución, etc.). Estas políticas deben soportar a todos los usuarios permitiendo el acceso controlado a los datos y garantizando el nivel de análisis requerido por distinto perfiles (desde generar informes a aplicar ciencia de datos).
- Disponer de un catálogo centralizado e indexado del inventario de datos (y metadatos) que incluya: fuentes, versiones, veracidad y precisión de los datos. Sería deseable que este catálogo permitiese reflejar la cardinalidad de los datos (cómo se relacionan con otros) y, además, guardar la traza de los datos. El data lake deberá facilitar en todos los casos la adaptación fácil a los cambios: a la inclusión de nuevas fuentes, a nuevas formas de analizar los datos.
- Mostrarse cómo un almacén único de datos fácil de gestionar y de compartir por todas las aplicaciones y, accesible desde todos los dispositivos. Este interfaz único debería facilitar el acceso a todos los datos en todos los formatos que sean requeridos. A su vez, será el usuario quién decidirá qué datos la interesan (explora) y cómo los relaciona.
- Soportar la relación de analítica ágil tanto desde como en el data-lake: utilizando múltiples aproximaciones analítica y flujos de datos.
- Asegurar la eficiencia incluyendo el borrado selectivo, la compresión o la de-duplicación de datos.
- Soportar que los datos no vayan al proceso si no que el proceso vaya a los datos.
Un data lake puede contener información de logs de servidores y aplicaciones, de sensores de datos (IoT, Internet de las Cosas), datos de bajo nivel de consumidores (p.e. clics en una web), datos de redes sociales, colecciones de documentos (mails, manuales de usuarios, informes, etc.), datos de geolocalización y geolocalizados, imágenes, video, audio, fotos, etc.
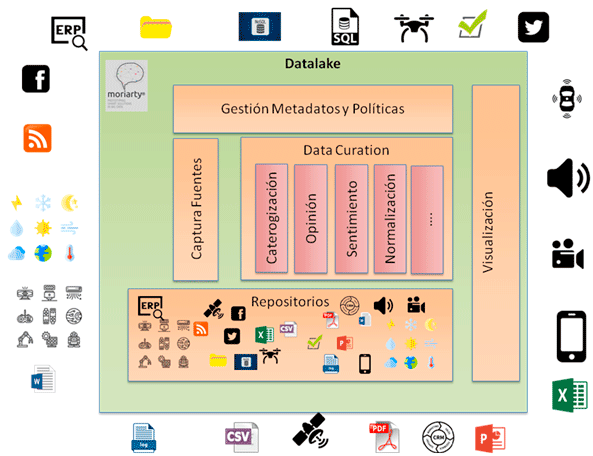
Esquema conceptual de un data lake
Proceso de Creación de un Data Lake
Aunque no existe una metodología estándar el proceso de creación de un data lake, se debería considerar los siguientes pasos:
Adquisición de Datos:
Obtención de datos y metadatos, así como su preparación para una eventual inclusión en el data lake. Este proceso, identificar las fuentes y los conjuntos de datos que son de mayor valor para un determinado proceso, puede ser muy exigente. Consiste en determinar, que datos, con qué granularidad (nivel de detalle), cuál es la frecuencia con la qué se pueden obtener o si se pueden leer de una vez, etc. Para realizarse bien, hay que tener un conocimiento adecuado del uso que se quiere dar a los datos de cara a anticipar las necesidades de los usuarios.
Tras identificar las fuentes y los datos a obtener, otro factor a considerar, son los términos y condiciones bajo los que están licenciados. Para comprender la licencia, el usuario debe poder contestar a las siguientes preguntas: ¿Qué datos se licencias y cómo o dónde se hacen disponibles?; ¿Los datos son gratuitos o hay algún coste asociado con su acceso? Si hay coste, ¿cómo se aplica (todo incluido, periódicamente, por dato accedido, etc.)?; ¿Qué usos están permitidos por la licencia?; ¿Qué riesgos asume la empresa al aceptar la licencia?
Una vez que se está seguro de que es legal y cómo es legal acceder a los datos, el siguiente reto es transferirlos físicamente de la fuente al data lake: realizar una copia. Bien a través de una API que devuelve resultados a una consulta o a través de un mecanismo de descarga masiva. Tras acceder al conjunto de datos deseados es labor del data lake verificar su contenido (que la descarga ha sido completa), actualizar las versiones del contenido, etc.
Para que el conjunto de datos incorporados sea completamente usable es necesario describirlo, dotarlo de metadatos que permitan responder a un usuario a las siguientes preguntas: ¿Cómo está representado el dato?; ¿De dónde vienen los datos?; ¿Cuánto tiempo tienen esos datos?; ¿Pueden conectarse estos datos a los datos de los que ya dispongo?
Responder estas preguntas requiere metadatos de distintos tipos: esquemáticos, para definir el formato y relaciones entre conjuntos de datos; semánticos, dando significado a datos con independencia de su formato y permitiendo establecer relaciones entre conjuntos de datos que en apariencia no la tienen; metadatos describiendo la idiosincrasia del conjunto de datos (cómo interpretarlos).
Data Curation/Grooming Data:
Es el conjunto de procesos/pasos por los que los datos crudos son transformados en datos consumibles por las aplicaciones analíticas. Para ello toman en consideración los metadatos obtenidos en el paso anterior y aplican transformaciones a los datos para que puedan ser utilizados en un punto anterior. Son cosas tan “sencillas” como transformar un fichero csv en una matriz o, más complejas, como capturar el contenido de una hoja de cálculo compleja u obtener el texto de un PDF y categorizarlo o, todavía más complejas, como integrar conjuntos de datos. Otros procesos asociados podrían ser la normalización de datos o la generación de datos derivados aplicando técnicas de inteligencia artificial. Un aspecto importante a considerar es la necesidad de guardar el proceso seguido especificándolo todo lo posible tanto para los pasos como para los datos (versiones, formatos, etc.).
Provisión de Datos:
Son el conjunto de procesos que permiten acceder a los datos contenidos en el data lake de acuerdo con las políticas que tiene establecidas. Para evitar el acceso a datos inapropiados, el data lake debería proveer un modo de visualización de conjuntos de datos que permitiese determinar (por sus excepciones, contenido, etc.) su adecuación a un determinado fin. Por lo general, junto con los datos debería poder visualizarse la metainformación de los mismos, incluyendo el contexto de los datos, de cara a que el usuario pueda entenderlo y utilizarlos adecuadamente en sus análisis. Finalmente, una vez el usuario ha seleccionado el conjunto de datos de su interés, antes de que pueda ser extraído sacado del data lake debería informársele de las políticas y licencias que atañen a su uso.
Preservación de los Datos:
Son el conjunto de procesos y políticas que determinan qué datos deben conservarse, hasta cuándo y cuáles no. Otros objetivos de estos procesos es determinar cómo debe evolucionar la infraestructura para garantizar la disponibilidad de suficiente espacio y el rendimiento adecuado para acceder a los datos.
Ejemplos de data lakes
En ITAINNOVA estamos contribuyendo a generar data lakes en proyectos tanto de investigación como de aplicación, para clientes de distintos sectores y, utilizando los datos allí incluidos para alcanzar distintos objetivos.
Entre otros muchos proyectos, algunos ejemplos son:
- SHION-CloudiFacturing (Horizon2020 R&D programme -Grant No. 768892) que despliega en el Cloud un sistema de predicción de errores en la inyección de plásticos basado en las datos de las máquinas de Thermolympic capturados por el sistema MES que BMS Vision.
- Innoalimen es un proyecto en el ITAINNOVA participa desarrollando una herramienta de monitorización y análisis de Redes Sociales para determinar qué temas relacionados con el ámbito de la alimentación saludable están candentes en cada momento.
- AGROLAKE: el objetivo de este proyecto desarrollado para PAINTEC es capturar la información relevante para la gestión de explotaciones agrarias aplicando agricultura de precisión.
- MATUROLIFE es otro proyecto europeo (Horizon2020 R&D programme -Grant No. 760789) que tiene como objetivo el desarrollo de tecnología para la asistencia que permita a personas mayores vivir en entornos urbanos de una manera independiente y confortable. Para ello introduce sensores que monitorizan su día a día y utilizan los datos para evaluar su estado, guiarles o recomendarles acciones que mejoren su bienestar.
- GRAPEVINE: hiGh peRformAnce comPuting sErvices for preVentIon and coNtrol of pEsts in fruit crops (G.A. CEF – TELECOMMUNICATIONS SECTOR AGR. No INEA/CEF/ICT/A2018/1837816), trata de generar modelos inteligentes multifactoriales para predecir el desarrollo vegetativo de la vides y de posibles pestes que pueden afectarles y que utiliza un data lake en el que se incorporan los datos de observaciones de técnicos agrícolas, datos climatológicos reales y previstos así como, imágenes y derivados de las mismas capturadas por la misión Sentinel 2 de la red europea Copernicus.
Artículo validado por:
ita
OTROS ARTÍCULOS
-

-

Componentes del coche eléctrico: Desarrollo e implicaciones técnicas
Viernes, 24 Enero 2025
- Diseño y desarrollo de vehículos eficientes